
Fixing YouTube Search with OpenAI’s Whisper
OpenAI’s Whisper is a new state-of-the-art (SotA) model in speech-to-text. It is able to almost flawlessly transcribe speech across dozens of languages and even handle poor audio quality or excessive background noise.
The domain of spoken word has always been somewhat out of reach for ML use-cases. Whisper changes that for speech-centric use cases. We will demonstrate the power of Whisper alongside other technologies like transformers and vector search by building a new and improved YouTube search.
Search on YouTube is good but has its limitations, especially when it comes to answering questions. With trillions of hours of content, there should be an answer to almost every question. Yet, if we have a specific question like “what is OpenAI’s CLIP?”, instead of a concise answer we get lots of very long videos that we must watch through.
What if all we want is a short 20-second explanation? The current YouTube search has no solution for this. Maybe there’s a good reason to encourage users to watch as much of a video as possible (more ads, anyone?).
Whisper is the solution to this problem and many others involving the spoken word. In this article, we’ll explore the idea behind a better speech-enabled search.
The Idea
We want to get specific timestamps that answer our search queries. YouTube does support time-specific links in videos, so a more precise search with these links should be possible.
Timestamp URLs can be copied directly from a video, we can use the same URL format in our search app.
To build something like this, we first need to transcribe the audio in our videos to text. YouTube automatically captions every video, and the captions are okay — but OpenAI just open-sourced something called “Whisper”.
Whisper is best described as the GPT-3 or DALL-E 2 of speech-to-text. It’s open source and can transcribe audio in real-time or faster with unparalleled performance. That seems like the most exciting option.
Once we have our transcribed text and the timestamps for each text snippet, we can move on to the question-answering (QA) part. QA is a form of search where given a natural language query like “what is OpenAI’s Whisper?” we can return accurate natural language answers.
We can think of QA as the most intuitive form of searching for information because it is how we ask other people for information. The only difference being we type the question into a search bar rather than verbally communicate it — for now.
How does all of this look?
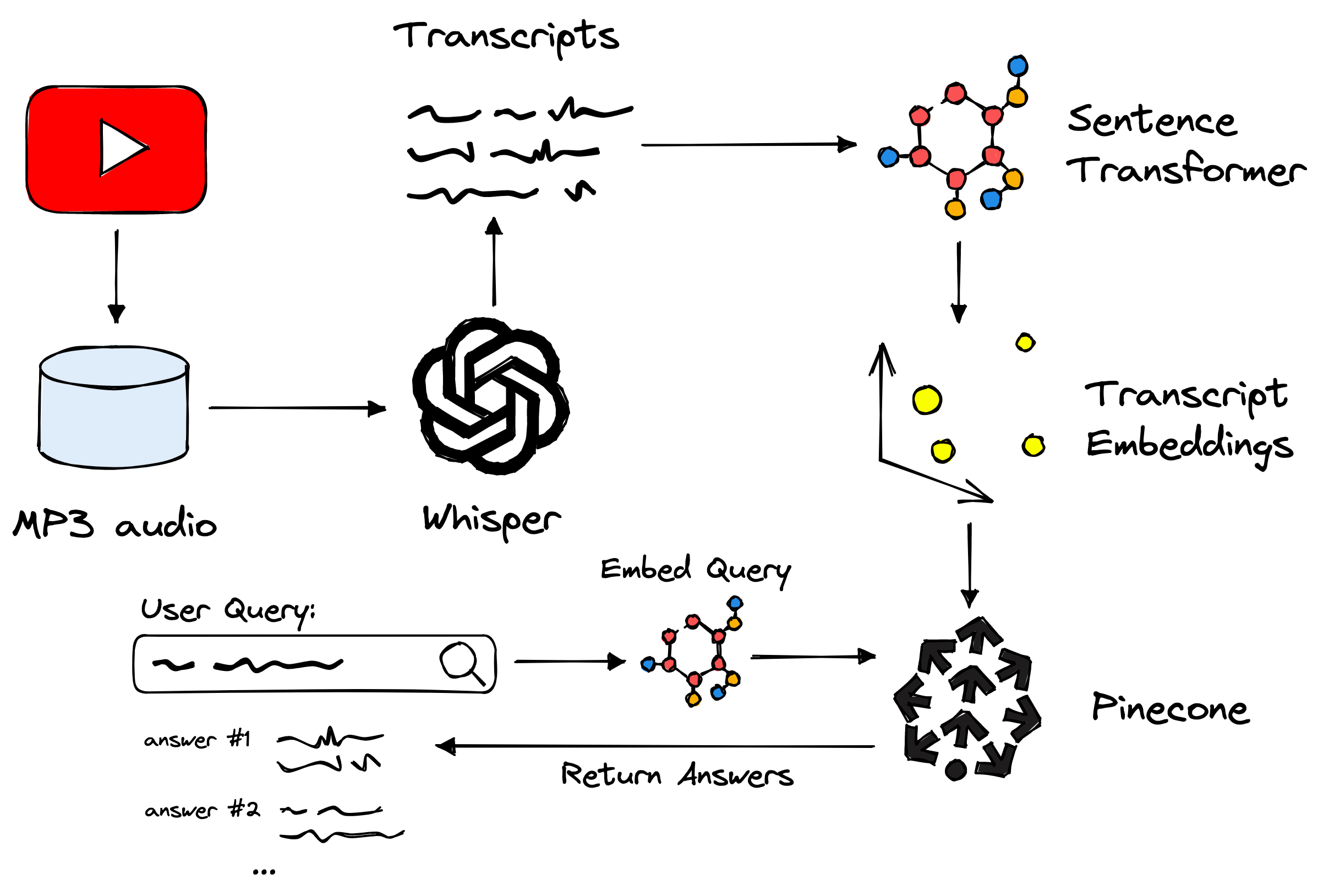
Overview of the process used in our demo. Covering OpenAI’s Whisper, sentence transformers, the Pinecone vector database, and more.
Now let’s color in the details and walk through the steps.
Video Data
The first step is to download our YouTube video data and extract the audio attached to each video. Fortunately, there’s a Python library for exactly that called pytube.
With pytube, we provide a video ID (found in the URL bar or downloadable if you have a channel). I directly downloaded a summary of channel content, including IDs, titles, publication dates, etc., via YouTube. This same data is available via Hugging Face Datasets in a dataset called jamescalam/channel-metadata.
We’re most interested in the Title and Video ID fields. With the video ID, we can begin downloading the videos and saving the audio files with pytube.
| from pytube import YouTube # !pip install pytube | |
| from pytube.exceptions import RegexMatchError | |
| from tqdm.auto import tqdm # !pip install tqdm | |
| # where to save | |
| save_path = “./mp3” | |
| for i, row in tqdm(videos_meta): | |
| # url of video to be downloaded | |
| url = f”https://youtu.be/{row[‘Video ID’]}“ | |
| # try to create a YouTube vid object | |
| try: | |
| yt = YouTube(url) | |
| except RegexMatchError: | |
| print(f”RegexMatchError for ‘{url}‘”) | |
| continue | |
| itag = None | |
| # we only want audio files | |
| files = yt.streams.filter(only_audio=True) | |
| for file in files: | |
| # from audio files we grab the first audio for mp4 (eg mp3) | |
| if file.mime_type == ‘audio/mp4’: | |
| itag = file.itag | |
| break | |
| if itag is None: | |
| # just incase no MP3 audio is found (shouldn’t happen) | |
| print(“NO MP3 AUDIO FOUND”) | |
| continue | |
| # get the correct mp3 ‘stream’ | |
| stream = yt.streams.get_by_itag(itag) | |
| # downloading the audio | |
| stream.download( | |
| output_path=save_path, | |
| filename=f”{row[‘Video ID’]}.mp3″ | |
| ) |
After this, we should find ~108 audio MP3 files stored in the ./mp3 directory.
Downloaded MP3 files in the ./mp3 directory.
With these, we can move on to transcription with OpenAI’s Whisper.
Speech-to-Text with Whisper
OpenAI’s Whisper speech-to-text-model is completely open source and available via OpenAI’s Whisper library available for pip install via GitHub:
!pip install git+https://github.com/openai/whisper.gitWhisper relies on another software called FFMPEG to convert video and audio files. The installation for this varies by OS [1]; the following cover the primary systems:
# on Ubuntu or Debian sudo apt update && sudo apt install ffmpeg # on Arch Linux sudo pacman -S ffmpeg # on MacOS using Homebrew (https://brew.sh/) brew install ffmpeg # on Windows using Chocolatey (https://chocolatey.org/) choco install ffmpeg # on Windows using Scoop (https://scoop.sh/) scoop install ffmpegAfter installation, we download and initialize the large model, moving it to GPU if CUDA is available.
| import whisper | |
| import torch # install steps: pytorch.org | |
| device = “cuda” if torch.cuda.is_available() else “cpu” | |
| model = whisper.load_model(“large”).to(device) |
Other models are available, and given a smaller GPU (or even CPU) should be considered. We transcribe the audio like so:
From this, we have a list of ~27K transcribed audio segments, including text alongside start and end seconds. If you are waiting a long time for this to process, a pre-built version of the dataset is available. Download instructions are in the following section.
The last cell from above is missing the logic required to extract and add the metadata from our videos_dict that we initialized earlier. We add that like so:
| data = [] | |
| for i, path in enumerate(tqdm(paths)): | |
| _id = path.split(‘/’)[–1][:–4] | |
| # transcribe to get speech-to-text data | |
| result = model.transcribe(path) | |
| segments = result[‘segments’] | |
| # get the video metadata… | |
| video_meta = videos_dict[_id] | |
| for segment in segments: | |
| # merge segments data and videos_meta data | |
| meta = { | |
| **video_meta, | |
| **{ | |
| “id”: f”{_id}-t{segments[j][‘start’]}“, | |
| “text”: segment[“text”].strip(), | |
| “start”: segment[‘start’], | |
| “end”: segment[‘end’] | |
| } | |
| } | |
| data.append(meta) |
After processing all of the segments, they are saved to file as a JSON lines file with:
| import json | |
| with open(“youtube-transcriptions.jsonl”, “w”, encoding=“utf-8”) as fp: | |
| for line in tqdm(data): | |
| json.dump(line, fp) | |
| fp.write(‘\n‘) |
With that ready, let’s build the QA embeddings and vector search component.
Question-Answering
On Hugging Face Datasets, you can find the data I scraped in a dataset called jamescalam/youtube-transcriptions:
For now, the dataset only contains videos from my personal channel, but I will add more videos from other ML-focused channels in the future.
The data includes a short chunk of text (the transcribed audio). Each chunk is relatively meaningless:
Ideally, we want chunks of text 4-6x larger than this to capture enough meaning to be helpful. We do this by simply iterating over the dataset and merging every six segments.
A few things are happening here. First, we’re merging every six segments, as explained before. However, doing this alone will likely cut a lot of meaning between related segments.
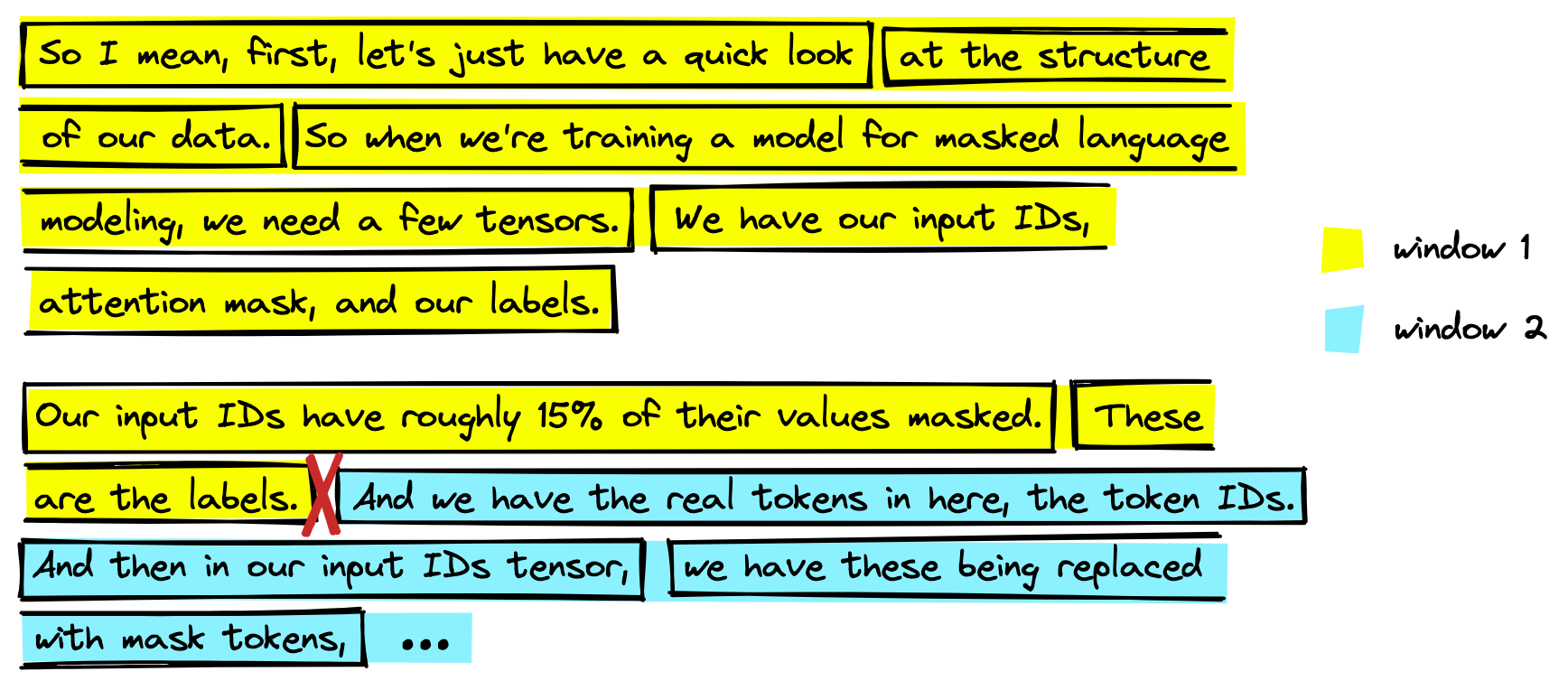
Even when merging segments we’re still left with a point where we must split the text (annotated with red cross-mark above). This can lead to us missing important information.
A common technique to avoid cutting related segments is adding some overlap between segments, where stride is used. For each step, we move three segments forward while merging six segments. By doing this, any meaningful segments cut in one step will be included in the next.
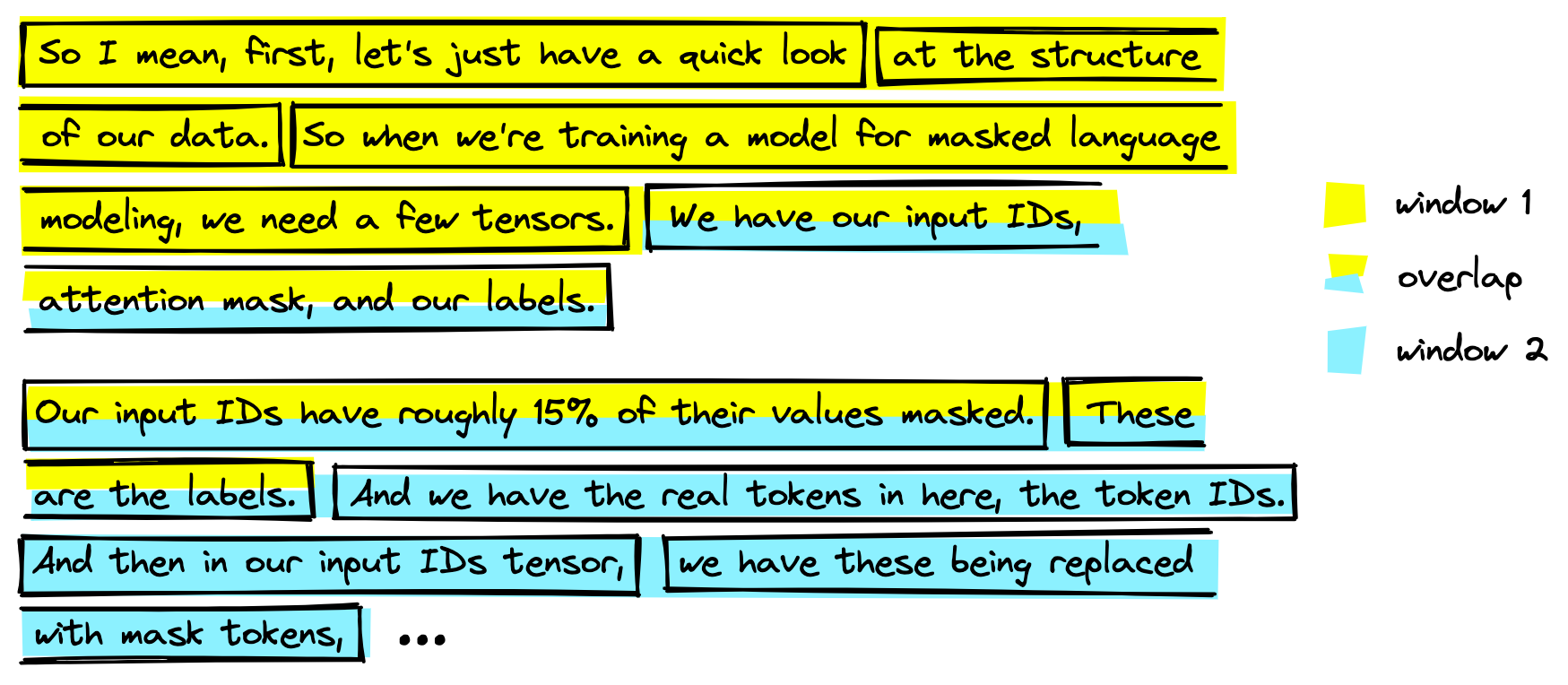
We can avoid this loss of meaning by adding an overlap when merging segments. It returns more data but means we are much less likely to cut between meaning segments.
With this, we have larger and more meaningful chunks of text. Now we need to encode them with a QA embedding model. Many high-performing, pretrained QA models are available via Hugging Face Transformers and the Sentence Transformers library. We will use one called multi-qa-mpnet-base-dot-v1.
Using this model, we can encode a passage of text to a meaningful 768-dimensional vector with model.encode("<some text>"). Encoding all of our segments at once or storing them locally would require too much compute or memory — so we first initialize the vector database where they will be stored:
We should see that the index (vector database) is currently empty with a total_vector_count of 0. Now we can begin encoding our segments and inserting the embeddings (and metadata) into our index.
That is everything we needed to prepare our data and add everything to the vector database. All that is left is querying and returning results.
Making Queries
Queries are straightforward to make; we:
- Encode the query using the same embedding model we used to encode the segments.
- Pass to query to our index.
We do that with the following:
These results are relevant to the question; three, in particular, are from a similar location in the same video. We might want to improve the search interface to be more user-friendly than a Jupyter Notebook.
One of the easiest ways to get a web-based search UI up and running is with Hugging Face Spaces and Streamlit (or Gradio if preferred).
We won’t go through the code here, but if you’re familiar with Streamlit, you can build a search app quite easily within a few hours. Or you can use our example and do it in 5-10 minutes.
When querying again for "what is OpenAI's clip?" we can see that multiple results from a single video are merged. With this, we can jump to each segment by clicking on the part of the text that is most interesting to us.
Try a few more queries like:
What is the best unsupervised method to train a sentence transformer? What is vector search? How can I train a sentence transformer with little-to-no data?We can build incredible speech-enabled search apps very quickly using Whisper alongside Hugging Face, sentence transformers, and Pinecone’s vector database.
Whisper has unlocked a entire modality — the spoken word — and it’s only a matter of time before we see a significant increase in speech-enabled search and other speech-centric use cases.
Both machine learning and vector search have seen exponential growth in the past years. These technologies already seem like sci-fi. Yet, despite the incredible performance of everything we used here, it’s only a matter of time before all of this gets even better.