
Microsoft’s AI VALL-E Can Clone Your Voice From a 3-Second Audio Clip
The technology, while impressive, would make it easy for cybercriminals to clone people’s voices for scam and identity fraud purposes.
A new artificial intelligence advancement from Microsoft can clone your voice after hearing you speak for a mere 3 seconds.
The program, called VALL-E(Opens in a new window), was designed for text-to-speech synthesis. A team of researchers at Microsoft created it by having the system listen to 60,000 hours of English audiobook narration from over 7,000 different speakers in a bid to get it to reproduce human-sounding speech. This sample is hundreds of times larger than what other text-to-speech programs have been built on.
The Microsoft team published a website(Opens in a new window) that includes several demos of VALL-E in action. As you can hear, the AI program can not only clone someone’s voice using a 3-second audio clip, but also manipulate the clone voice to say whatever is desired. In addition, the program can replicate emotion in a person’s voice or be configured into different speaking styles.
Human Speaker:
VALL-E:
Human Speaker:
VALL-E:
Voice cloning is nothing new. But Microsoft’s approach stands out by making it easy to replicate anyone’s voice with only a short snippet of audio data. Hence, it’s not hard to imagine the same technology fueling cybercrime—which the Microsoft team acknowledges as a potential threat.
“Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker,” the researchers wrote in their paper. That said, the team notes it might be possible to build programs that can “discriminate whether an audio clip was synthesized by VALL-E.”
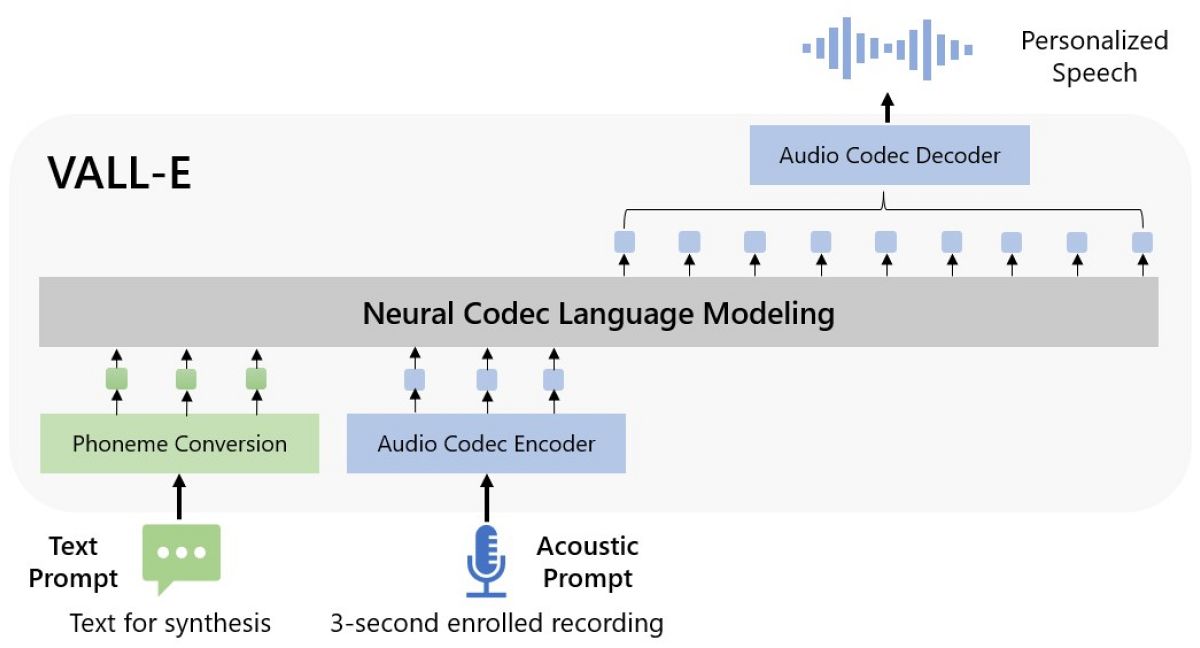
VALL-E interprets audio speech as “discrete tokens,” and then reproduces the token to speak with different text. “VALL-E generates the corresponding acoustic tokens conditioned on the acoustic tokens of the 3-second enrolled recording,” the researchers wrote. “Finally, the generated acoustic tokens are used to synthesize the final waveform with the corresponding neural codec decoder.”
However, the technology is far from perfect. In their research paper, Microsoft’s team notes VALL-E can sometimes struggle or fail to pronounce certain words. At other times, the words can sound gargled, artificially synthesized, robotic or just tonally off.
Human Speaker:
VALL-E:
“Even if we use 60K hours of data for training, it still cannot cover everyone’s voice, especially accent speakers,” the team added. “Moreover, the diversity of speaking styles is not enough, as LibriLight (the audio VALL-E was trained on) is an audiobook dataset, in which most utterances are in reading style.”
Nevertheless, the research suggests creating an even more accurate voice cloning program is achievable if it’s trained on even more audio clips. In the meantime, it doesn’t appear Microsoft has released VALL-E to the public, likely to guard against misuse.

Microsoft’s New AI Can Simulate Anyone’s Voice From a 3-Second Sample
By John P. Mello Jr. , Vanessa Bates Ramirez, Michael Kan, Oguz, Ananya Gairola, Benzinga, Julia Musto source source source source source source
Microsoft’s new language model Vall-E is reportedly able to imitate any voice using just a three-second sample recording.
The recently released AI tool was tested on 60,000 hours of English speech data. Researchers said in a paper out of Cornell University that it could replicate the emotions and tone of a speaker.
Those findings were apparently true even when creating a recording of words that the original speaker never actually said.
The Vall-E samples shared on GitHub are eerily similar to the speaker prompts, although they range in quality.
In one synthesized sentence from the Emotional Voices Database, Vall-E sleepily says the sentence: “We have to reduce the number of plastic bags.”
However, the research in text-to-speech AI comes with a warning.
“Since Vall-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker,” the researchers say on that web page. “We conducted the experiments under the assumption that the user agree to be the target speaker in speech synthesis. When the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model.”At the moment, Vall-E, which Microsoft calls a “neural codec language model,” is not available to the public.
AI is being used to generate everything from images to text to artificial proteins, and now another thing has been added to the list: speech. Last week researchers from Microsoft released a paper on a new AI called VALL-E that can accurately simulate anyone’s voice based on a sample just three seconds long. VALL-E isn’t the first speech simulator to be created, but it’s built in a different way than its predecessors—and could carry a greater risk for potential misuse.
Most existing text-to-speech models use waveforms (graphical representations of sound waves as they move through a medium over time) to create fake voices, tweaking characteristics like tone or pitch to approximate a given voice. VALL-E, though, takes a sample of someone’s voice and breaks it down into components called tokens, then uses those tokens to create new sounds based on the “rules” it already learned about this voice. If a voice is particularly deep, or a speaker pronounces their A’s in a nasal-y way, or they’re more monotone than average, these are all traits the AI would pick up on and be able to replicate.
The model is based on a technology called EnCodec by Meta, which was just released this part October. The tool uses a three-part system to compress audio to 10 times smaller than MP3s with no loss in quality; its creators meant for one of its uses to be improving the quality of voice and music on calls made over low-bandwidth connections.
To train VALL-E, its creators used an audio library called LibriLight, whose 60,000 hours of English speech is primarily made up of audiobook narration. The model yields its best results when the voice being synthesized is similar to one of the voices from the training library (of which there are over 7,000, so that shouldn’t be too tall of an order).
 Besides recreating someone’s voice, VALL-E also simulates the audio environment from the three-second sample. A clip recorded over the phone would sound different than one made in person, and if you’re walking or driving while talking, the unique acoustics of those scenarios are taken into account.
Besides recreating someone’s voice, VALL-E also simulates the audio environment from the three-second sample. A clip recorded over the phone would sound different than one made in person, and if you’re walking or driving while talking, the unique acoustics of those scenarios are taken into account.
Some of the samples sound fairly realistic, while others are still very obviously computer-generated. But there are noticeable differences between the voices; you can tell they’re based on people who have different speaking styles, pitches, and intonation patterns.
The team that created VALL-E knows it could very easily be used by bad actors; from faking sound bites of politicians or celebrities to using familiar voices to request money or information over the phone, there are countless ways to take advantage of the technology. They’ve wisely refrained from making VALL-E’s code publicly available, and included an ethics statement at the end of their paper (which won’t do much to deter anyone who wants to use the AI for nefarious purposes).
It’s likely just a matter of time before similar tools spring up and fall into the wrong hands. The researchers suggest the risks that models like VALL-E will present could be mitigated by building detection models to gauge whether audio clips are real or synthesized. If we need AI to protect us from AI, how do know if these technologies are having a net positive impact? Time will tell.
Microsoft researchers have announced a new application that uses artificial intelligence to ape a person’s voice with just seconds of training. The model of the voice can then be used for text-to-speech applications.
The application called VALL-E can be used to synthesize high-quality personalized speech with only a three-second enrollment recording of a speaker as an acoustic prompt, the researchers wrote in a paper published online on arXiv, a free distribution service and an open-access archive for scholarly articles.
There are programs now that can cut and paste speech into an audio stream, and that speech is converted into a speaker’s voice from typed text. However, the program must be trained to emulate a person’s voice, which can take an hour or more.
“One of the standout things about this model is it does that in a matter of seconds. That’s very impressive,” Ross Rubin, the principal analyst at Reticle Research, a consumer technology advisory firm in New York City, told TechNewsWorld.
According to the researchers, VALL-E significantly outperforms existing state-of-the-art text-to-speech (TTS) systems in both speech naturalness and speaker similarity.
Moreover, VALL-E can preserve a speaker’s emotions and acoustic environment. So if a speech sample were recorded over a phone, for example, the text using that voice would sound like it was being read through a phone.
‘Super Impressive’
VALL-E is a noticeable improvement over previous state-of-the-art systems, such as YourTTS, released in early 2022, said Giacomo Miceli, a computer scientist and creator of a website with an AI-generated, never-ending discussion featuring the synthetic speech of Werner Herzog and Slavoj Žižek.
“What is interesting about VALL-E is not just the fact that it needs only three seconds of audio to clone a voice, but also how closely it can match that voice, the emotional timbre, and any background noise,” Miceli told TechNewsWorld. Ritu Jyoti, group vice president for AI and automation at IDC, a global market research company, called VALL-E “significant and super impressive.”
“This is a significant improvement over previous models, which require a much longer training period to generate a new voice,” Jyoti told TechNewsWorld.
“It is still the early days for this technology, and more improvements are expected to have it sound more human-like,” she added.
Emotion Emulation Questioned
Unlike OpenAI, the maker of ChatGPT, Microsoft hasn’t opened VALL-E to the public, so questions remain about its performance. For example, are there factors that could cause degradation of the speech produced by the application?
“The longer the audio snippet generated, the higher the chances that a human would hear things that sound a little bit off,” Miceli observed. “Words may be unclear, missed, or duplicated in speech synthesis.”
“It’s also possible that switching between emotional registers would sound unnatural,” he added.
The application’s ability to emulate a speaker’s emotions also has skeptics. “It will be interesting to see how robust that capability is,” said Mark N. Vena, president and principal analyst at SmartTech Research in San Jose, Calif.
“The fact that they claim it can do that with simply a few seconds of audio is difficult to believe,” he continued, “given the current limitations of AI algorithms, which require much longer voice samples.”
Why It’s Important: Unlike how OpenAI provided chatGPT for others to experiment with, Microsoft seems cautious of VALL-E’s capabilities to fuel deceptive circumstances.
The research paper stated, “Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker.”
The company said a detection model could be built to authenticate whether VALL-E synthesized an audio clip.
VALL-E: The AI tool that can replicate any voice
Microsoft recently released an artificial intelligence tool known as VALL-E that can replicate people’s voices. The tool uses just a 3-second recording of a specific voice as a prompt to generate content, and it was trained on 60,000 hours of English speech data. The AI model is capable of replicating the emotions and tone of a speaker, even when creating a recording of words that the original speaker never said.

This is a significant advancement in the field of AI-generated speech, as previous models were only able to replicate the voice, but not the emotions or tone of the speaker. A paper out of Cornell University used VALL-E to synthesize several voices, and some examples of the work are available on GitHub. While the voice samples shared by Microsoft range in quality, some sound natural, while others are clearly machine-generated and sound robotic. However, as AI technology continues to improve, the generated recordings will likely become more convincing.
However, there are concerns about the ethical implications of this technology. As artificial intelligence becomes more powerful, the voices generated by VALL-E and similar technologies will become more convincing, which could open the door to realistic spam calls that replicate the voices of real people that a potential victim knows. Politicians and other public figures could also be impersonated, which could lead to false information being spread on social media.
In addition, there are security concerns. Some banks use voice recognition technology to verify the identity of a caller, but if AI-generated voices become more convincing, it could become more difficult to detect if a caller is using a VALL-E voice. Additionally, the technology may also impact voice actors, as their services may no longer be needed if AI-generated voices become more realistic.
VALL-E is an impressive AI tool that has the potential to revolutionize the field of voice synthesis. However, it also raises several ethical and security concerns. It will be important for companies like Microsoft to develop measures to regulate the use of VALL-E to ensure it is used for good, and not for malicious purposes.
Ethical Concerns
Experts see beneficial applications for VALL-E, as well as some not-so-beneficial. Jyoti cited speech editing and replacing voice actors. Miceli noted the technology could be used to create editing tools for podcasters, customize the voice of smart speakers, as well as being incorporated into messaging systems and chat rooms, videogames, and even navigation systems.
“The other side of the coin is that a malicious user could clone the voice of, say, a politician and have them say things that sound preposterous or inflammatory, or in general to spread out false information or propaganda,” Miceli added.
Vena sees enormous abuse potential in the technology if it’s as good as Microsoft claims. “At the financial services and security level, it’s not difficult to conjure up use cases by nefarious actors that could do really damaging things,” he said.
Jyoti, too, sees ethical concerns bubbling around VALL-E. “As the technology advances, the voices generated by VALL-E and similar technologies will become more convincing,” she explained. “That would open the door to realistic spam calls replicating the voices of real people that a potential victim knows.”
“Politicians and other public figures could also be impersonated,” she added.
“There could be potential security concerns,” she continued. “For example, some banks allow voice passwords, which raises concerns about misuse. We could expect an arms race escalation between AI-generated content and AI-detecting software to stop abuse.”
“It is important to note that VALL-E is currently not available,” Jyoti added. “Overall, regulating AI is critical. We’ll have to see what measures Microsoft puts in place to regulate the use of VALL-E.”
 Enter the Lawyers
Enter the Lawyers
Legal issues may also arise around the technology. “Unfortunately, there may not be current, sufficient legal tools in place to directly tackle such issues, and instead, a hodgepodge of laws that cover how the technology is abused may be used to curtail such abuse,” said Michael L. Teich, a principal in Harness IP, a national intellectual property law firm.
“For example,” he continued, “voice cloning may result in a deepfake of a real person’s voice that may be used to trick a listener to succumb to a scam or may even be used to mimic the voice of an electoral candidate. While such abuses would likely raise legal issues in the fields of fraud, defamation, or election misinformation laws, there is a lack of specific AI laws that would tackle the use of the technology itself.”
“Further, depending on how the initial voice sample was obtained, there may be implications under the federal Wiretap Act and state wiretap laws if the voice sample was obtained over, for example, a telephone line,” he added.
“Lastly,” Teich noted, “in limited circumstances, there may be First Amendment concerns if such voice cloning was to be used by a governmental actor to silence, delegitimize or dilute legitimate voices from exercising their free speech rights.”
“As these technologies mature, there may be a need for specific laws to directly address the technology and prevent its abuse as the technology advances and becomes more accessible,” he said.
Making Smart Investments
In recent weeks, Microsoft has been making AI headlines. It’s expected to incorporate ChatGPT technology into its Bing search engine this year and possibly into its Office apps. It’s also reportedly planning to invest $10 million in OpenAI — and now, VALL-E.
“I think they’re making a lot of smart investments,” said Bob O’Donnell, founder and chief analyst of Technalysis Research, a technology market research and consulting firm in Foster City, Calif.
“They jumped on the OpenAI bandwagon several years ago, so they’ve been behind the scenes on this for quite a while. Now it’s coming out in a big way,” O’Donnell told TechNewsWorld.
“They’ve had to play catch-up with Google, who’s known for its AI, but Microsoft is making some aggressive moves to come to the forefront,” he continued. “They’re jumping on the popularity and the incredible coverage that all these things have been getting.”
Rubin added, “Microsoft, having been the leader in productivity in the last 30 years or so, wants to preserve and extend that lead. AI could hold the key to that.”
VALL-E: The AI tool that can replicate any voice
 Microsoft recently released an artificial intelligence tool known as VALL-E that can replicate people’s voices. The tool uses just a 3-second recording of a specific voice as a prompt to generate content, and it was trained on 60,000 hours of English speech data. The AI model is capable of replicating the emotions and tone of a speaker, even when creating a recording of words that the original speaker never said.
Microsoft recently released an artificial intelligence tool known as VALL-E that can replicate people’s voices. The tool uses just a 3-second recording of a specific voice as a prompt to generate content, and it was trained on 60,000 hours of English speech data. The AI model is capable of replicating the emotions and tone of a speaker, even when creating a recording of words that the original speaker never said.

This is a significant advancement in the field of AI-generated speech, as previous models were only able to replicate the voice, but not the emotions or tone of the speaker. A paper out of Cornell University used VALL-E to synthesize several voices, and some examples of the work are available on GitHub. While the voice samples shared by Microsoft range in quality, some sound natural, while others are clearly machine-generated and sound robotic. However, as AI technology continues to improve, the generated recordings will likely become more convincing.
However, there are concerns about the ethical implications of this technology. As artificial intelligence becomes more powerful, the voices generated by VALL-E and similar technologies will become more convincing, which could open the door to realistic spam calls that replicate the voices of real people that a potential victim knows. Politicians and other public figures could also be impersonated, which could lead to false information being spread on social media.
In addition, there are security concerns. Some banks use voice recognition technology to verify the identity of a caller, but if AI-generated voices become more convincing, it could become more difficult to detect if a caller is using a VALL-E voice. Additionally, the technology may also impact voice actors, as their services may no longer be needed if AI-generated voices become more realistic.
VALL-E is an impressive AI tool that has the potential to revolutionize the field of voice synthesis. However, it also raises several ethical and security concerns. It will be important for companies like Microsoft to develop measures to regulate the use of VALL-E to ensure it is used for good, and not for malicious purposes.
The technology, while impressive, would make it easy for cybercriminals to clone people’s voices for scam and identity fraud purposes.
The program, called VALL-E(Opens in a new window), was designed for text-to-speech synthesis. A team of researchers at Microsoft created it by having the system listen to 60,000 hours of English audiobook narration from over 7,000 different speakers in a bid to get it to reproduce human-sounding speech. This sample is hundreds of times larger than what other text-to-speech programs have been built on.
The Microsoft team published a website(Opens in a new window) that includes several demos of VALL-E in action. As you can hear, the AI program can not only clone someone’s voice using a 3-second audio clip, but also manipulate the clone voice to say whatever is desired. In addition, the program can replicate emotion in a person’s voice or be configured into different speaking styles.
Human Speaker:
VALL-E:
Human Speaker:
VALL-E:
Voice cloning is nothing new. But Microsoft’s approach stands out by making it easy to replicate anyone’s voice with only a short snippet of audio data. Hence, it’s not hard to imagine the same technology fueling cybercrime—which the Microsoft team acknowledges as a potential threat.
“Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker,” the researchers wrote in their paper. That said, the team notes it might be possible to build programs that can “discriminate whether an audio clip was synthesized by VALL-E.”
VALL-E interprets audio speech as “discrete tokens,” and then reproduces the token to speak with different text. “VALL-E generates the corresponding acoustic tokens conditioned on the acoustic tokens of the 3-second enrolled recording,” the researchers wrote. “Finally, the generated acoustic tokens are used to synthesize the final waveform with the corresponding neural codec decoder.”
However, the technology is far from perfect. In their research paper, Microsoft’s team notes VALL-E can sometimes struggle or fail to pronounce certain words. At other times, the words can sound gargled, artificially synthesized, robotic or just tonally off.
Check it out https://valle-demo.github.io/
LibriSpeech Samples
| Text | Speaker Prompt | Ground Truth | Baseline | VALL-E |
|---|---|---|---|---|
| They moved thereafter cautiously about the hut groping before and about them to find something to show that Warrenton had fulfilled his mission. | ||||
| And lay me down in thy cold bed and leave my shining lot. | ||||
| Number ten, fresh nelly is waiting on you, good night husband. | ||||
| Yea, his honourable worship is within, but he hath a godly minister or two with him, and likewise a leech. | ||||
| Instead of shoes, the old man wore boots with turnover tops, and his blue coat had wide cuffs of gold braid. | ||||
| The army found the people in poverty and left them in comparative wealth. | ||||
| Thus did this humane and right minded father comfort his unhappy daughter, and her mother embracing her again, did all she could to soothe her feelings. | ||||
| He was in deep converse with the clerk and entered the hall holding him by the arm. |
VCTK Samples
| Text | Speaker Prompt | Ground Truth | Baseline | VALL-E |
|---|---|---|---|---|
| We have to reduce the number of plastic bags. | ||||
| So what is the campaign about? | ||||
| My life has changed a lot. | ||||
| Nothing is yet confirmed. | ||||
| I could hardly move for the next couple of days. | ||||
| His son has been travelling with the Tartan Army for years. | ||||
| Her husband was very concerned that it might be fatal. | ||||
| We’ve made a couple of albums. |
Synthesis of Diversity
Thanks to the sampling-based discrete token generation methods, given a pair of text and speaker prompts, VALL-E can synthesize diverse personalized speech samples with different random seeds.
| Text | Speaker Prompt | VALL-E Sample1 | VALL-E Sample2 |
|---|---|---|---|
| Because we do not need it. | |||
| I must do something about it. | |||
| He has not been named. | |||
| Number ten, fresh nelly is waiting on you, good night husband. |
Acoustic Environment Maintenance
VALL-E can synthesize personalized speech while maintaining the acoustic environment of the speaker prompt. The audio and transcriptions are sampled from the Fisher dataset.
| Text | Speaker Prompt | Ground Truth | VALL-E |
|---|---|---|---|
| I think it’s like you know um more convenient too. | |||
| Um we have to pay have this security fee just in case she would damage something but um. | |||
| Everything is run by computer but you got to know how to think before you can do a computer. | |||
| As friends thing I definitely I’ve got more male friends. |
Speaker’s Emotion Maintenance
VALL-E can synthesize personalized speech while maintaining the emotion in the speaker prompt. The audio prompts are sampled from the Emotional Voices Database.
| Text | Emotion | Speaker Prompt | VALL-E |
|---|---|---|---|
| We have to reduce the number of plastic bags. | Anger | ||
| Sleepy | |||
| Neutral | |||
| Amused | |||
| Disgusted |
More Samples
We randomly selected some transcriptions and 3s audio segments from LibriSpeech test-clean set as the text and speaker prompts and then use VALL-E to synthesize the personalized speech. Note that the transcriptions and audio segments are from different speakers, there is no ground truth speech for reference.
| Text | Speaker Prompt | VALL-E |
|---|---|---|
| The others resented postponement, but it was just his scruples that charmed me. | ||
| Notwithstanding the high resolution of hawkeye, he fully comprehended all the difficulties and danger he was about to incur. | ||
| We were more interested in the technical condition of the station than in the commercial part. | ||
| Paul takes pride in his ministry not to his own praise but to the praise of god. | ||
| The ideas also remain but they have become types in nature forms of men animals birds fishes. | ||
| Other circumstances permitting that instinct disposes men to look with favor upon productive efficiency and on whatever is of human use. | ||
| But suppose you said I’m fond of writing, my people always say my letters home are good enough for punch. | ||
| He summoned half a dozen citizens to join his posse who followed obeyed and assisted him. |
Ethics Statement
Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agree to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model.
This Article was updated with a list of Competitors
Comparing the Best Computer Voice Generators
Voice.ai
Play.ht
Azure.microsoft.com
Murf.ai
Vall-e.io
Bottalk.io
uberduck.ai
Voicemod.net
Veritonevoice.com
Podcastle.ai
Resemble.ai
My Own Voice
Lovo.ai
Descript.com
Cereproc.com
Whisper
Spik.ai
Respeecher
Speechify
Speechelo
Synthesys.io
Spik.ai
Bigspeak.ai
Replica
Woord
Clipchamp
Voicera
Natural Reader
Search our site for any articles about voice cloning here
below check out our other articles over the years on the topic:
Microsoft’s New AI Can Simulate Anyone’s Voice From a 3-Second Sample
The Rise Of Voice Cloning And DeepFakes In The Disinformation Wars
What is Voice Cloning and How Does It Work?
Ai Voice Cloning : How does it work and where is it used?
Copy That: Realistic Voice Cloning with Artificial Intelligence
The Era of Voice Cloning: What It Is & How to Get Your Voice Cloned
What is Voice Cloning and How Does It Work?